The Automated CIO
I previously wrote a bit about our internal infrastructure in my post on The Art of Automation. This post is going to go into details about our automated Chief infrastructure Officer (CIO). I joke so much that I automated our CIO that I even named the repo holding the code… cio.
I took the time this weekend to finally clean up some of this code. Previously, our infrastructure was held together with bash, popsicle sticks, glue, and some rust. Now, it is mostly rust and a much more sane architecture to grok. We also get the freedom of caching all our data in a database that we own so we can access it even when services are down. Previously, we called out to each service’s API for every script, bot, or whatever, which can get expensive, slow, and potentially be riddled with rate limits, or worse, downtime.
Let me give you a diagram of what this looks like now:
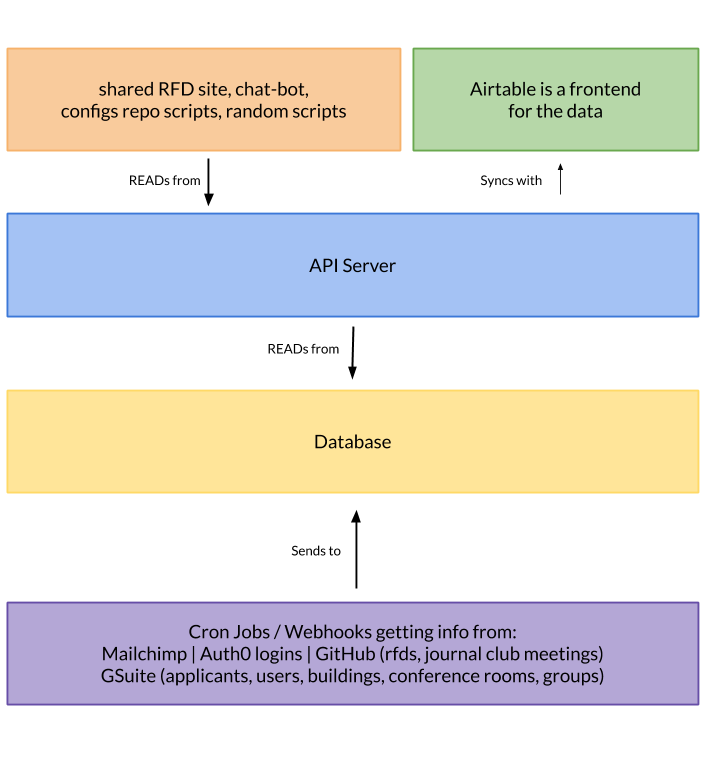
Sending data to the database
At the very bottom of the diagram, you can see where we are using webhooks and cron jobs to pull data out of various services APIs and send it to the database.
Let’s dive into a few of these because it is not as simple as a pipe from an API to a database in most cases.
Applicants
Every applicant to Oxide completes our candidate materials. This is a series of questions about things they’ve worked on. Those get submitted with their resume and other details into a Google Form.
A cron job parses the spreadsheet from the Google Form. In doing so, it knows if an application is new and we need to send an email to the applicant that we received it. It will also send an email to the team that we got a new application.
The cron job also parses the materials they submitted and their resume into plain text. Materials can be in the form of HTML, PDF, doc, docx, zip, and even PDF with zip headers ;). The resume and each question in the materials is saved in individual database columns, which makes search and indexing easier when we want to find an application based on something we remember from their materials or resume.
When an applicant gets hired or moved into an interview phase, GitHub issues are opened so we can keep track of their progress through the interview or onboarding.
RFDs
We wrote about our RFD process on the Oxide blog in RFD 1 Requests for Discussion.
Each RFD is written in either markdown or asciidoc. We collect the content for each RFD and update it in the database along with its equivalent HTML.
The HTML is used for generating pages in a small website we use for sharing RFDs with folks external to Oxide. These might be friends of Oxide, engineers who we value their expertise and feedback, or potential customers and partners.
By having all the content stored in the database it also makes it easier to search across the content in all the RFDs.
Those are just two examples of APIs we build on top of and enrich as we move data into our database.
GitHub
It’s nice to have a cache of certain GitHub API calls for when GitHub is down or we get rate limited. We store a few GitHub endpoints data in our database as well.
Utilizing the data in an easy way
Next, we need a way to share all this data with other bots, scripts, fellow colleagues, and apps within the company. This is where the API server comes into play.
The API server acts as the middle-man between the database and any scripts, bots, users, and apps. The API is read-only since we get all the data from external services and APIs.
The API server syncs the database data with Airtable so we can use Airtable as a front-end for viewing all the data in a specific table at once. This turns out to be a great use for Airtable because you can also do joins with other tables in Airtable very easily. It makes for a nice visual experience.
For example, we can relate an RFD from the RFD table to an item in a different table related to the roadmap. As folks push changes to their RFDs, the RFD content will update in Airtable as well.
All in all, this was pretty fun to build, refactor, build, and refactor again. It’s been something I can pick up and work on when I get a free second and easily add functionality to when we want to use our data in a specific way.
For the API server, I got to use our dropshot REST API library for this! Thanks to Dave and Adam for writing that :)
At this point, I can’t imagine working at a company without an internal API for querying everything from Google groups, to applicants, to mailing list subscribers, to RFDs, and more. That’s all for now! I’d love to hear about other ideas you might have for internal infrastructure!