Hard Multi-Tenancy in Kubernetes
EDIT: See my post on a design doc for a multi-tenant orchestrator instead. I wrote this when an internal requirement was to use Kubernetes but I do not personally think you should use Kubernetes for this use case.
Kubernetes is the new kernel. We can refer to it as a “cluster kernel” versus the typical operating system kernel. This means a lot of great things for users trying to deploy applications. It also leads to a lot of the same challenges we have already faced with operating system kernels. One of which being privilege isolation. In Kubernetes, we refer to this as multi-tenancy, or the dream of being able to isolate tenants of a cluster.
The models for multi-tenancy have been discussed at length in the community’s multi-tenancy working group. NOTE: to view most of these Google docs you need to be a member of the kubernetes-wg-multitenancy Google group. There have also been some proposals offered to solve each model. The current model of tenancy in Kubernetes assumes the cluster is the security boundary. You can build a SaaS on top of Kubernetes but you need to bring your own trusted API and not just use the Kubernetes API. Of course, with that comes a lot of considerations you must also think about when building your cluster securely for a SaaS even.
The model I am going to be focusing on for this post is “hard multi-tenancy.” This implies that tenants do not trust each other and are assumed to be actively malicious and untrustworthy. Hard multi-tenancy means multiple tenants in the same cluster should not have access to anything from other tenants. In this model, the goal is to have the security boundary be the Kubernetes namespace object.
The hard multi-tenancy model has not been solved yet, but there have been a few proposals. All systems have weaknesses and nothing is perfect. With a system as complex and large as Kubernetes it is hard to trust the entire system to not be vulnerable. In this regard and in the regard of the existing proposals, one single exploit in Kubernetes leads to full supervisor privileges and then it’s game over.
This is not an acceptable way to secure a system and guarantee isolation between tenants. I will cover in this post why having more than one layer of security is so important.
The attack surface with the highest risk of logical vulnerabilities is the Kubernetes API. This must be isolated between tenants. The attack surface with the highest risk of remote code execution are the services running in containers. These must also be isolated between tenants.
If you take one look at the open source repository and the speed to which Kubernetes is growing, it is already taking on a lot of the same aspects of the monolithic kernels of Windows, Mac OS X, Linux, and FreeBSD. Fortunately, there have already been a lot of solutions to privilege separation in monolithic kernels researched and implemented.
The solution I am going to focus on is Nested Kernel: Intra-Kernel Isolation. This paper solves the problem of privilege isolation in monolithic kernels by nesting a small kernel inside the monolithic kernel.
More than One Layer of Security Required
What we know of today as “sandboxes” are defined as having multiple layers of
security. For example, the sandbox I made for the
contained.af playground has
security layers defined by seccomp, apparmor, kernel namespaces, cgroups,
capabilities, and an unprivileged Linux user. All those layers don’t necessarily
overlap, but a few do. If a user was to have an apparmor or seccomp bypass and
they tried to call mount inside the container, the Linux capability of
CAP_SYS_ADMIN would still prevent them from executing mount.
These layers ensure that one vulnerability in the system does not take out the entire security of the system. We need this for hard multi-tenancy in Kubernetes as well. This is why all the existing proposals are insufficient. We need at least two layers and these comprise only one.
With intra-kernel isolation applied to Kubernetes, we get two layers. Let me dive in a bit deeper into how this would work.
Isolation via Namespaces
The existing proposals for hard multi-tenancy assume that the security boundary for multiple users on Kubernetes would be the namespace. “Namespace” in this regard being those defined by Kubernetes. The proposals all have the weakness that if you exploit one part of Kubernetes you can then have privileges to transverse namespaces and therefore transverse the tenants.
With Intra-Kernel Isolation, the namespace would still be the security boundary. However, instead of all sharing the main Kubernetes system services, each namespace would have it’s own “nested” Kubernetes system services. Meaning the api-server, kube-proxy, etc would all be running individually in a pod in that namespace. The tenant who deploys to that namespace would then have no access to the actual root-level Kubernetes system services but merely the ones running in their namespace. An exploit in Kubernetes would not be game over for the whole system, but only game-over within that namespace.
Another security boundary would also be the container isolation itself. These
pods could be further locked down by the existing resources like
PodSecurityPolicy and NetworkPolicy. With the ever growing innovation in
the ecosystem, you could even run VMs (katacontainers) for hardware-isolation
between containers giving you the highest level of security between the services
in your cluster.
For those familiar with Linux namespaces you can think of this as a clone
for Kubernetes. The design is roughly similar.
For example on linux cloning new namespaces looks like:
clone(CLONE_NEWNS | CLONE_NEWIPC | CLONE_NEWUTS | CLONE_NEWNET | CLONE_NEWPID… )
So when you create a new Kubernetes namespace with intra-kernel isolation this roughly translates to, purely example not to be taken literally:
clone(CLONE_NEWAPISERVER | CLONE_NEWKVSTORE | CLONE_NEWKUBEPROXY | CLONE_NEWKUBEDNS…)
In Linux, namespaces control what a process can see. This holds true for users designated to a namespace in Kubernetes. Since each namespace would have its own system services that would be all they could see.
Unlike the pseudo code above, the Kubernetes namespace will automatically get new components of each system service. This is more in line with the design of Solaris Zones or FreeBSD Jails.
In my blog post Setting the Record Straight: containers vs. Zones vs. Jails vs. VMs, I go over the differences between those various isolation techniques. In this design, we are more inline with that of Zones or Jails. Containers come with all the parts. The namespaces in Kubernetes should automatically set up a well isolated world, just like that of Zones or Jails without the user having to worry about if they configured it correctly.
Another problem with namespaces in Linux is that not everything is namespaced. This design ensures that every part of Kubernetes is isolated per tenant.
Isolation via Resource Control
There are still a few unanswered questions just with the design above alone.
Let’s take a look at another control mechanism in Linux: cgroups.
Cgroups control what a process can use. They are the masters of resource control.
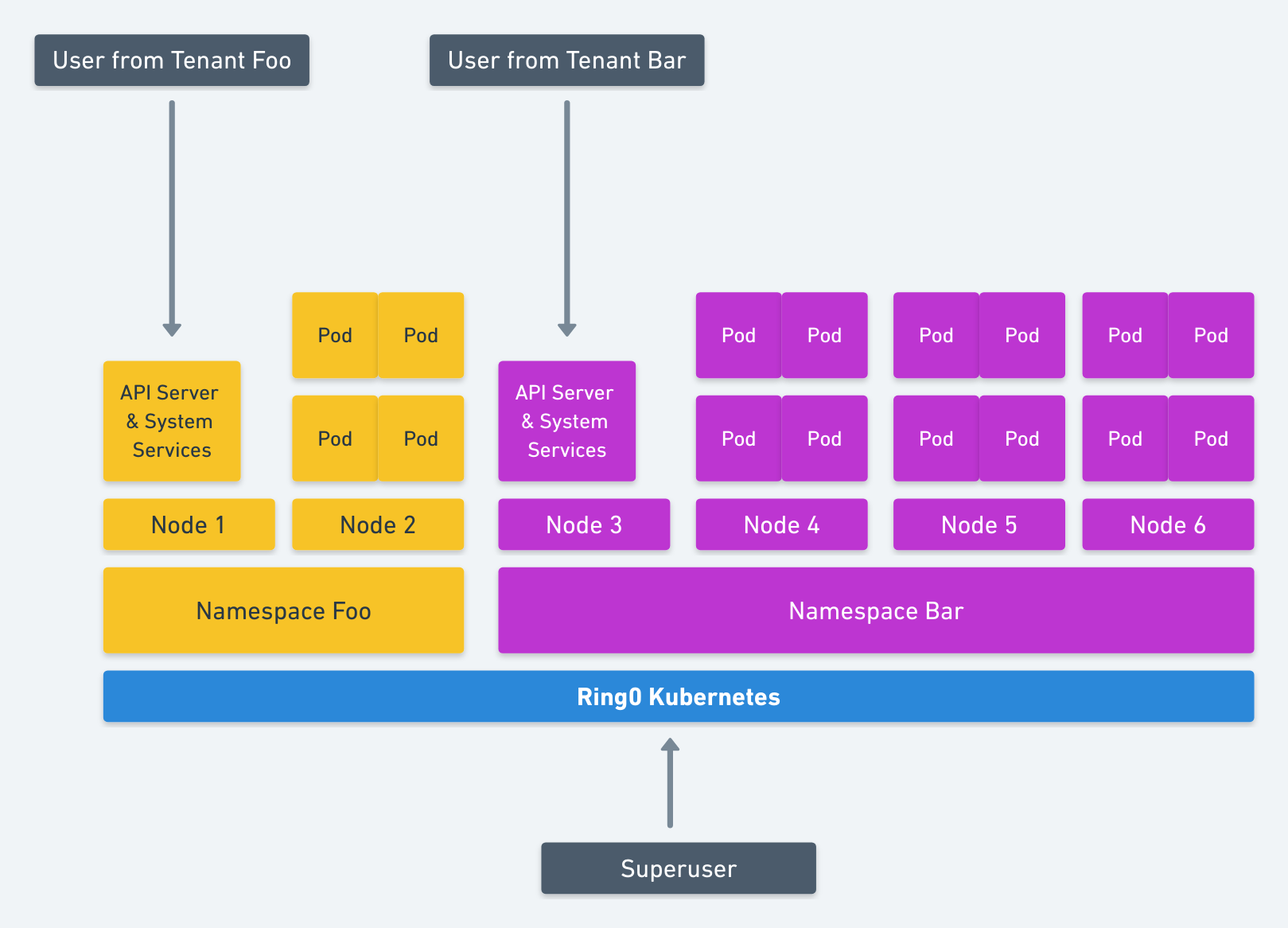
This concept would need to be applied to Kubernetes namespaces as well. Rather than controlling resources like memory consumption and CPU, it would apply to nodes. The tenant within a namespace would only be able to access certain nodes designated to it. All the namespace services would be isolated at the machine level as well. No services from different tenants would run on the same machine. This could always be a setting in the future but the default should be that nodes are not shared.
This model allows for designating to our nested API server a set of kubelets on various nodes to use.
At this point we have isolation of what a tenant can see (Kubernetes namespace) and what they can use (nodes designated to a namespace).
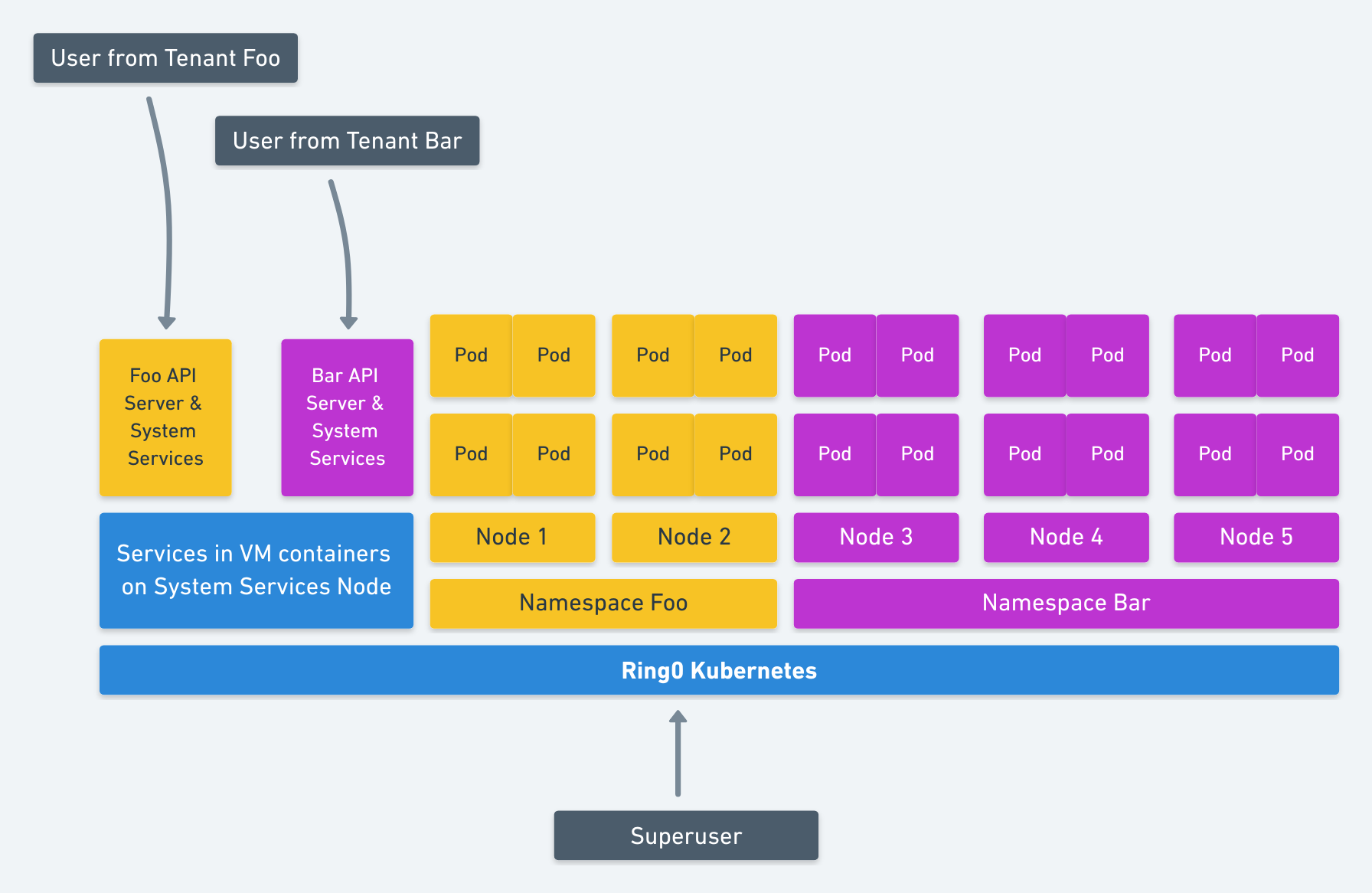
Alternatively, if the system services for the namespaces were isolated with nested VM containers (katacontainers) and you considered all the other variables outlined in this design doc. Then those services could share nodes. This would give you a bit better resource utilization than above. It is illustrated below.
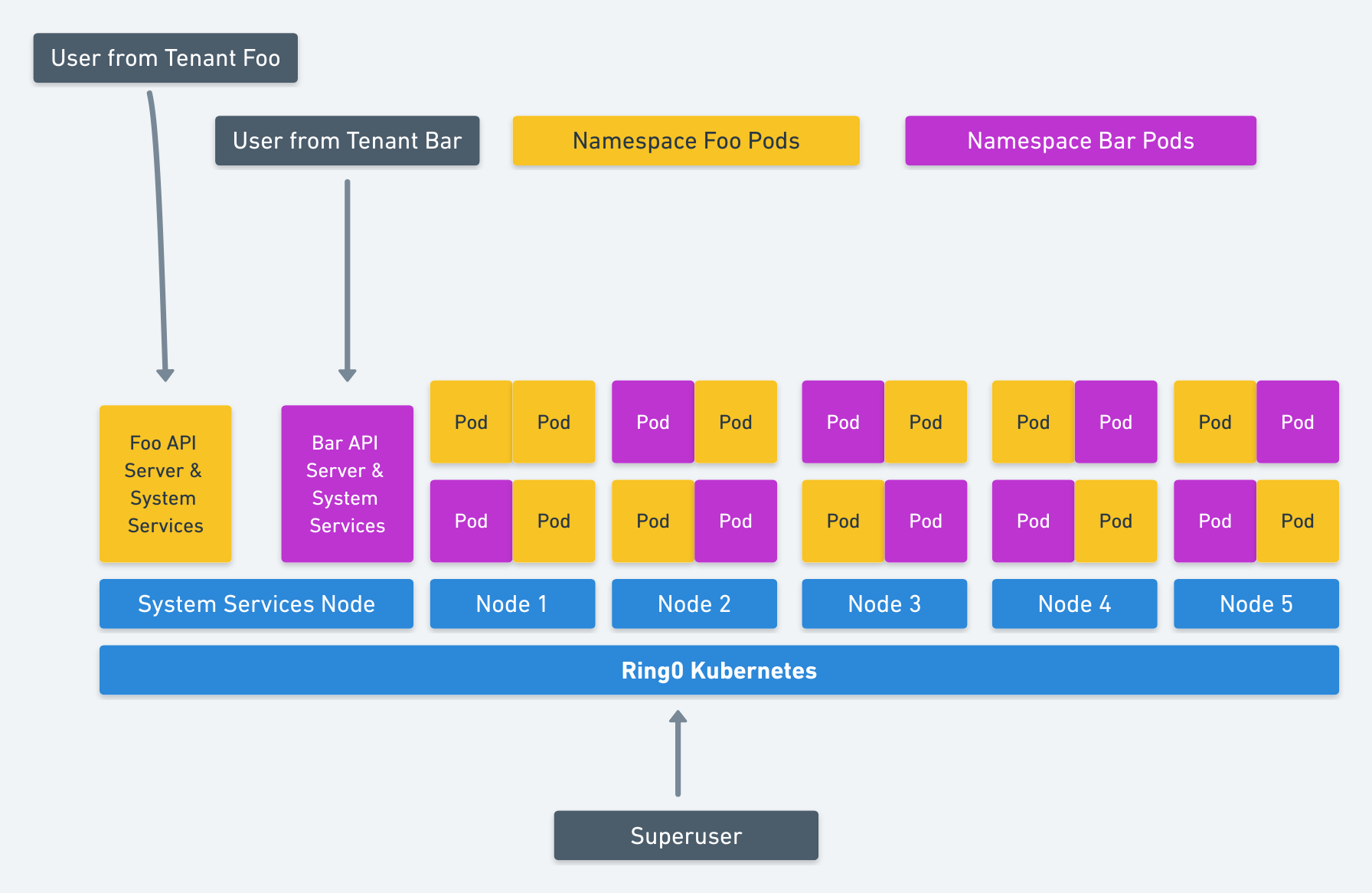
Taking it even a step further for even better resource utilization, if you isolated the whole system and containers into fully sandboxed or VM containers as per this design doc, then all services could share nodes. This is illustrated below.
Tenants that Span Multiple Namespaces
A few times it has been brought up in the working group that tenants might need to span multiple namespaces. While I don’t believe this should be a default, I don’t see a problem with it.
Let’s take a look again at how namespaces work in Linux and how we use them
for containers. Each namespace is a file descriptor. You can share a namespace
between containers by designating the file descriptor for the namespace you want
to share and calling setns.
In Kubernetes, we could implement the same sort of design. A superuser can delegate a namespace is to be shared between tenants with access to that namespace.
Overall this design uses the expertise from past art of kernel isolation techniques. It is also designed with the lessons learned from past kernel isolation techniques.
With the growing ecosystem and core of Kubernetes it’s important to have more than one layer of security between tenants. Security techniques such as failsafe defaults, complete mediation, least privilege, and least common mechanism are very popular but hard to apply to monolithic kernels. Kubernetes by default shares everything and has many different, sometimes very broken, drivers and plugins just like that of an operating system kernel. Applying the same isolation techniques of kernels to Kubernetes will allow for a better privilege isolation solution.
Where does this leave us?
We have fully isolated and solved our threat model in a very strong way. The attack surface with the highest risk of logical vulnerabilities, the Kubernetes API, has full logical separation in that each tenant has their own. The attack surface with the highest risk of remote code execution, containers themselves, have full virtualized separation from other tenants. This isolation either comes from isolating via designated nodes themselves to tenants or by running containers that use hardware isolation. The only viable path to other tenants is getting remote code execution in some service, then breaking out of the container (and/or VM).
The first diagram of intra-kernel isolation via node resource control illustrates close to the same as having two fully separate clusters operated by one superuser. Since nodes are designated to each tenant, you do not really gain more efficient resource utilization either.
The model with the highest gain of resource control comes from securely setting up your cluster to use nested virtual machines as containers or fully sandboxing the containers themselves so that the boundary is the container not the node. This eases the operators pain of running more than one cluster and allows resources to be used more effectively while also sustaining more than one layer of security.
None of this is set in stone. This is my idea for solving this problem. If you are interested in discussing this or other aspects of tenancy in Kubernetes please join the working group. I look forward to discussing this there. Thanks!